
Jetson Zero-Copy for Embedded ApplicationsJetson hardware platform from NVIDIA opens new opportunities for embedded applications. That mini supercomputer has just unbelievable set of hardware features together with stunning performance results. Powerful ARM processor, high performance internal GPU with CUDA and Tensor cores, various software libraries make it indispensable in embedded vision solutions. 
What is Zero-Copy at NVIDIA Jetson?Image acquisition stage is fundamental in every camera application. Usually, camera sends captured frames to system memory via external interface (GigE, USB3, CameraLink, CoaXPress (CXP), 10-GigE, Thunderbolt, PCIE, etc.). In high performance solutions we use GPU for further image processing, so we should copy these frames to GPU DRAM memory. This is the case for the conventional discrete GPU architecture (see Fig. 1). However, NVIDIA Jetson has integrated architecture. In Jetson hardware, CPU and GPU are placed on a single die, and they physically share the same system memory. Such architecture offers new opportunities for CPU-GPU communications, which are absent in discrete GPUs.
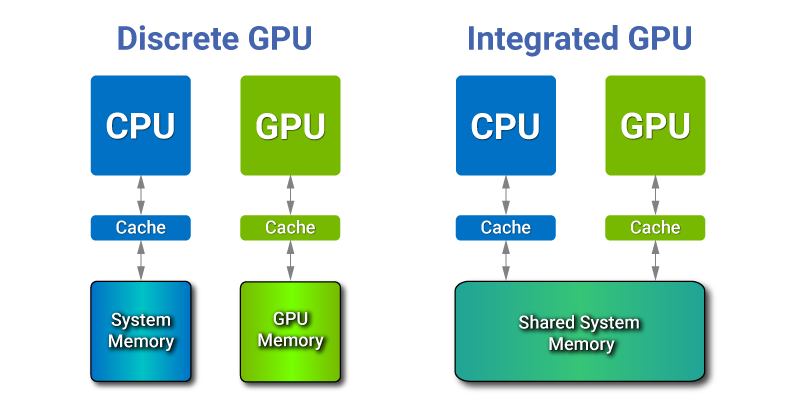
Fig.1. Discrete and Integrated GPU architectures
With integrated GPU the copy is obviously superfluous, since GPU use the same pool of physical memory as CPU. Still, we cannot simply ignore the copy in the general case, because software developers expect that writing to the source buffer on CPU will not affect data processing on GPU after that copy. That’s why we need a separate zero-copy scenario, when redundant copy can be avoided. In such scenario a data transfer over PCI-Express would only be used on systems with discrete GPU. Zero-copy means that we don't need to spend any time to copy data from host to device over PCIE, as we always have to do on any discrete laptop, desktop, server GPU. Basically, this is the way of how integrated GPU can take an advantage of DMA, shared memory and caches. That idea about eliminating extra data copy in camera applications appears promising, but in order to discuss the underlying methods, we first need to understand the concept of pinned memory in CUDA. What is Pinned Memory?Pinned (page-locked) memory is allocated for the CPU and prevents OS to move or swap it out to disk. It can be allocated by using cudaMallocHost function instead of the conventional malloc. Pinned memory provides higher transfer speed for GPU and allows asynchronous copying. Once pinned, that part of memory becomes unavailable to the concurrent processes, effectively reducing the memory pool available to the other programs and OS. CPU-GPU transfers via PCIE only occur using the DMA, which requires pinned buffers. But host (CPU) data allocations are pageable by default. So, when a data transfer from pageable host memory to device memory is invoked, the GPU driver must copy the host data to the pre-allocated pinned buffer and pass it to the DMA. We can avoid the excessive transfer between pageable and pinned host buffers by directly allocating our host arrays in pinned memory (see Fig. 2).
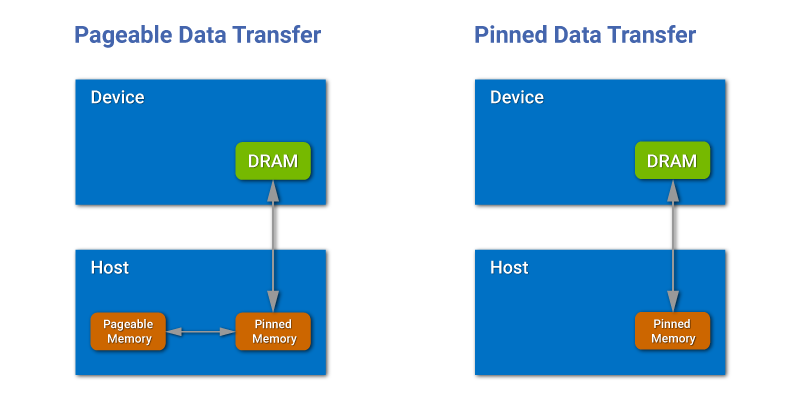
Fig.2. Copy from pageable memory and from pinned memory
To achieve zero-copy access on CUDA we always have to use “mapped” pinned buffers which are page-locked and also mapped into the CUDA address space. Mapped, pinned memory (zero-copy) is useful in the following cases
Mapped, pinned memory (zero-copy) is not useful
What is Unified Memory?Unified Memory in CUDA is a single memory address space accessible from any processor in a system (see Fig. 3). It is a hardware and software technology that allows allocating buffers that can be accessed from either CPU or GPU code without explicit memory copies. While traditional (not unified) memory model has been able to give the best performance, it requires very careful management of GPU resources and predictable access patterns. Zero-copy model has provided fine-grained access to the system memory, but in discrete GPU systems the performance is limited by the PCIE, and that model doesn’t allow to take advantage of data locality. Unified memory combines the advantages of explicit copies and zero-copy access: it gives to each processor an access to the system memory and automatically migrates the data on-demand so that all data accesses are fast. For NVIDIA Jetson it means avoiding of excessive copies as in the case of zero-copy memory. In order to use Unified Memory you just need to replace malloc() calls with cudaMallocManaged(), which returns universal pointer accessible from either CPU or GPU. On NVIDIA Pascal GPUs (or newer) you’ll also get support of hardware page faulting (which ensures migration of only those memory pages, which are actually accessed) and concurrent access from multiple processors.
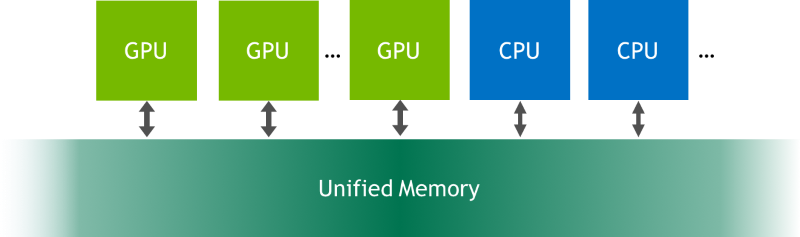
Fig.3. Unified memory (picture from https://devblogs.nvidia.com/unified-memory-cuda-beginners/)
On a 64-bit OS, where CUDA Unified Virtual Addressing (UVA) is in effect, there is no difference between pinned memory and zero-copy memory (i.e. pinned and mapped). This is because the UVA feature in CUDA causes all pinned allocations to be mapped by default. Zero-Copy in Jetson Image Processing ApplicationsIf we connect USB3 or PCIE camera to Jetson TX2 via USB/PCIE interface, we need to take into account that bandwidth of USB3 or PCIE interface is limited. Moreover, when using traditional memory access, a delay due to copy of captured images from CPU to GPU memory is unavoidable. But if we use zero-copy, that time is eventually hidden, so we get better performance and lower latency. We have to admit that zero-copy is not the only way to hide host-to-device copy time and to improve the total latency of the system. Another possible approach is overlapping image copy and image processing in different threads or processes. It will boost the throughput, but it will not improve the latency. Moreover, that approach is feasible only in concurrent CUDA Streams, which means that we have to create at least two independent pipelines in two CPU threads or processes. Unfortunately, it's not always possible, because of the limited size of GPU DRAM memory. One more way of reducing the cost of host-to-device transfer is the so-called GPU-Direct method, where data is sent directly from a camera driver to GPU via DMA. That approach requires driver modification, so this is the task for camera manufacturers, not for system integrators or third-party software developers. To summarize, zero-copy approach is very useful for integrated GPU, and it makes sense to use it in the image processing workflow, particularly for embedded camera applications on NVIDIA Jetson. This is easy and efficient way to improve the performance and to decrease the latency. Below we consider a real camera application, which is quite popular. Low-latency Jetson TX2 processing with live h264 RTSP streamingSince NVIDIA Jetson is so small and so powerful, it seems natural to use it for remote control in various applications. We can connect camera to Jetson, perform all processing on it, and send the processed data over wireless connection to another PC. There are fair chances to do that really fast and with low latency on Jetson. That solution has been implemented by MRTech company which is developing software for XIMEA cameras and NVIDIA Jetson. These are the key components of the solution:
Hardware features
Image processing pipeline on Jetson TX2 and Quadro P2000
Glass-to-glass video latencyTo check the latency of that solution, we have performed so-called glass-to-glass (G2G) latency test. The idea is to get the current time with high precision, to show it on a monitor with high refresh rate and to capture monitor picture with external camera, which sends data to Jetson for processing and streaming. Finally, we need to show on the same monitor the time when the new processed frame is exposed. We will see on the same monitor those two time values, so that their difference corresponds to a real latency of the system. Systematic error for such a method could be evaluated as half of camera exposure time plus half of monitor refresh time. In that case it's around (5 ms + 7 ms)/2 = 6 ms. On that video you can see the setup and live view of that solution. Originally, NVIDIA Jetson was connected to the main PC via cable, but later on it was switched to a wireless connection with the main PC. You can stop video to check the time difference between frames and evaluate the latency. On that video the averaged latency was about 60 ms, and we can consider that as great result. It means that the idea of remote control is viable, so we will proceed with further development. P.S. This is just a sample application to show what could be done on NVIDIA Jetson and to evaluate actual latency in the glass-to-glass test. Real use cases for two and more cameras could utilize any other image processing pipeline for your particular application. That solution could also be implemented for multi-camera systems. Other blog posts from Fastvideo about Jetson hardware and software
|